
Super Coding Addict
210106 WED 수업 - MySQL 문법(2) 본문
* 새로운 언어 공부방법
- 내가 끝까지 읽을 수 있는 입문서를 한 권 뗀다
- 레퍼런스 참조 (API)
- 그 언어로 게시판 정도 하나 만들어보기
* 데이터타입
- 컴퓨터 자원을 효율적으로 사용하기 위함(하드디스크 자원 절약), 검색시 검색속도도 물리적으로 빨라진다
- 숫자형
: 정수 타입(integer types)
//TINYINT : 1byte(8bit) , -128~127(signed) or 0~255(unsigned) ex)몸무게
:실수 형(float types)
//FLOAT(4byte) : 정수부+실수부 6자리
//DOUBLE(8byte) : 정수부+실수부 17자리
- 문자형
: CHAR(~255자까지)
//고정적인 저장공간 사용
: VARCHAR (variable character)
//가변적인 저장공간 사용
//글자 갯수보다 1byte 더 사용
: TEXT (256자이상)
//따로 저장공간 설정할 수 없는 데이터타입
- 날짜, 시간
: DATE
//날짜 저장
: DATETIME
// 날짜, 시간 저장
: TIMESTAMP
//DATATIME와 다른 점은 날짜 입력하지 않으면 현재 날짜와 시간을 자동으로 저장
: TIME
: YEAR
* CONSTRAINT 제약조건
- NOT NULL
: NULL 저장할 수 없음
- UNIQUE
: 하나의 컬럼에서 같은 값 저장 불가
- PRIMARY KEY
: NOT NULL && UNIQUE
: 하나의 테이블에 한번만 설정할 수 있음 --> why? PRIMARY KEY는 row데이터를 구분하는 용도로 쓰기 때문에
- FOREIGN KEY
: 다른 테이블과 연결되는 값이 저장됨
- DEFAULT
: 데이터저장시 해당 컬럼에 별도 저장값 없으면 DEFAULT에 설정된 값이 저장됨
- AUTO_INCREMENT
: 주로 PRIMARY키에 사용
: 별도 저장값이 없으면 숫자 +1
* FOREIGN KEY
- 잘못된 데이터입력을 사전에 방지할 수 있게 해줌
- 참조하는 테이블의 컬럼에 그 없는 데이터라면 입력 불가
* CRUD(Create, Read, Update, Delete) - DML, DDL 모두에 적용됨
- DML의 경우 Insert, Select, Update, Delete
- DDL의 경우 Create, Show, Alter, Drop
* CASE WHEN THEN ELSE
#국가별로 인구가 1억이상 "big", 5000만 이상 "medium", 5000만 이하 "small"
SELECT name, population,
CASE
WHEN population >= 10000 * 10000 THEN "big"
WHEN population >= 5000 * 10000 THEN "medium"
ELSE "small"
END AS scale
FROM country
ORDER BY population DESC;CASE - WHEN + 조건 + THEN + 조건에 맞는다면 표시할 내용 +
ELSE+ (조건 모두에 맞지 않는다면) 표시할 내용 + ELSE
* CONCAT
- 컬럼 또는 문자열 합치기
SELECT name, indepyear, CONCAT(name, "(", indepyear, ")")
FROM country
WHERE indepyear != "null";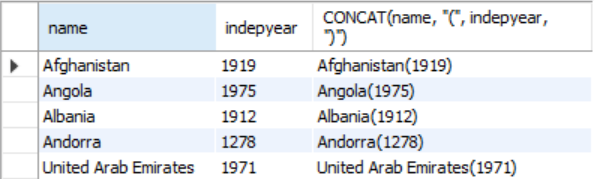
국가명(독립연도)를 출력하기 위해 CONCAT을 썼다.
문자열은 따옴표 안에 넣어주고 합칠 컬럼들을 순서대로 따옴표로 구분해 넣어주면 된다.
여기서 alias를 해주어서 as name(idpyear) 이런식으로 써주면 더 깔끔하겠다.
* WITH ROLLUP
select ifnull(customer_id, "total") as customer_id
, ifnull(staff_id, "total") as staff_id
, sum(amount) as amount
from payment
group by customer_id, staff_id
with rollup;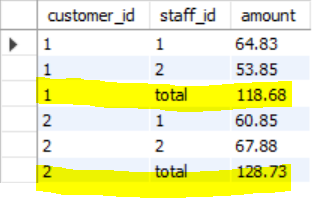
- 여러개의 컬럼을 group by한 후 각 컬럼의 데이터별로 총합을 row에 저장하는 방법
- 여기서는 customer_id로 먼저 그룹핑을 한 후, 다시 staff_id로 그룹핑을 하였다.
따라서 customer_id 1과 2에 대해 각각 staff_id 1과 2가 매칭이 되어 결과값으로 나오는데,
여기서 customer_id가 1일 때 amount를 모두 더해준 결과를 하나의 row로 밑에 출력을 해주는데 이게 바로 rollup
기능이다.
customer_id가 2일때도 마찬가지로 amount를 모두 더해준 결과를 row로 출력해준다.
* 변수선언, RANK
set @rank = 0;
select @rank := @rank + 1 as 'rank', name, population
from city
order by population desc
limit 3;
- 변수 선언 : SET @변수명 = 값;
- Oracle에는 RANK함수가 있으나, MySQL에는 없으므로 이런 방법으로 랭크를 해준다
:=는 row데이터가 하나 실행될 때마다 := 뒤의 절을 실행하게 되므로,
변수 rank에는 row 윗줄부터 +1이 된다. 초기값을 0으로 설정하였기에 1번째 row실행시 rank는 1이 된다.
limit 3로 3개의 데이터만 출력하여 1~3위만 뽑아온다.
여기서 @rank := @rank + 1를 rank로 alias해줄 때 RANK자체가 예약어에 있으므로 따옴표 안에 넣어준다.
이 쿼리문을 한번 더 실행하면 rank는 4,5,6으로 바뀌게 되는데 위에서 설명한 := 때문에 그렇다.
다시 set @rank = 0; 쿼리를 실행해 값을 초기화한 후 다시 쿼리문을 실행하면 1,2,3으로 바뀐다.
※ rank가 제대로 안되는 경우?
select @rank := @rank + 1 as 'rank', countrycode, count(*) as country_count
from city
group by countrycode
order by country_count desc
limit 5;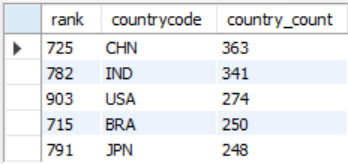
왜 이런 결과가 나왔을까? rank가 1-5위로 메겨져야 하는데, 뒤죽박죽스러운 rank가 나왔다.
이는 group by를 하기 전 select로 뽑아온 결과에 이미 rank가 메겨졌기 때문이다.
즉 countrycode별로 데이터들을 그룹화시키기 전에 나열된 결과에 rank가 메겨진 채로 group by가 되었기에
그 rank를 그대로 가져온 결과가 되어버렸다.
이를 해결하기 위해 서브쿼리를 써야한다.
//////
* CAST : 형변환
select name, gnp, cast(gnp as signed integer)
from country;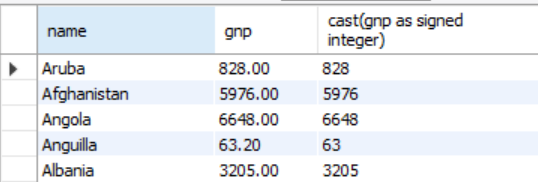
gnp는 원래 실수형 컬럼인데 CAST를 통해 정수형으로 형변환을 해주었다.
* 러버덕 디버깅
- 마치 동료에게 버그를 토로(?)하듯이 러버덕에게 어떤 버그가 생기는 지 리뷰를 하는 것이다. 가상의 인물 '동수'같은 존재... 사실 디버깅은 남의 시선으로 볼 때 진짜 빠르게 문제점이 캐치되어 이루어지는 경우가 많기에 이런 디버깅 방법도 추천.
#어제치 복습
# workbench 사용법
# 데이터베이스 모델링 : EER 다이어그램
# SQL문의 종류 : DML(데이터), DDL(데이터베이스, 테이블), DCL
# SELECT FROM : 데이터를 조회
# OPERATORS : 연산자 : 산술, 비교, 논리
# WHERE : 데이터를 특정 조건으로 필터링
# BETWWEEN A AND B, IN, NOT IN
# ORDER BY : 데이터를 정렬 : ASC, DESC
# LIMIT : 데이터를 조회할 때 조회되는 데이터의 수를 제한 : 5, 3
# DISTINCT : 데이터의 중복을 제거할 때 사용 -- 명령어 / 함수형태로 작성 가능
USE world;
SELECT DISTINCT(continent)
FROM country;
# 현재 데이터베이스 확인
SELECT database(); -- 인자값이 없는 함수
# 1byte = 8bit = 0000 0000 = 2^8(숫자로 표현할 수 있는 단위) = 256
USE ssac;
SHOW TABLES;
#정수형 데이터 타입
CREATE TABLE number1(
DATA TINYINT
);
DESC number1; -- 컬럼의 스키마(속성) 확인
# -128 ~ 127 (signed)
INSERT INTO number1 VALUE (127);
SELECT * FROM number1;
INSERT INTO number1 VALUE (128); -- 에러(out of range value)
CREATE TABLE number2(
data TINYINT UNSIGNED
);
DESC number2;
# 0 ~ 255 (unsigned)
INSERT INTO number2 VALUE (128);
SELECT * FROM number2;
# 실수형 데이터 타입
CREATE TABLE number3(
DATA FLOAT
);
DESC number3;
INSERT INTO number3 VALUE (12.3456789);
SELECT * FROM number3; -- 12.3457로 마지막 숫자 반올림되어 결과값 나옴
CREATE TABLE number4(
DATA DOUBLE
);
DESC number4;
INSERT INTO number4 VALUE (1234567890.1234567890);
# 전체 자릿수와 소수점 자리를 설정
# DECIMAL, NUMERIC
# DECIAML(5, 2) : 전체 자리수 5개, 소수점 2개
CREATE TABLE number5(
DATE DECIMAL(5,2)
);
DESC number5;
INSERT INTO number5 VALUE(123.56789); -- warning(지정한 자릿수와 맞지 X)
SELECT * FROM number5; -- 123.57 출력
# CHAR, VARCHAR
# ex) countrycode char(3)-->3byte / varchar(3) --> 4byte / ==> char가 유리
# ex) 나라이름 ==> varchar가 유리
# CHAR
CREATE TABLE str1(
DATA CHAR(255) -- 256일 때 에러
);
INSERT INTO str1 VALUE ("문자열입력");
SELECT * FROM str1;
# CREATE
# 데이터 베이스 생성
CREATE DATABASE test;
# 테이블 생성
# 제약조건이 없는 테이블 생성
USE test;
CREATE TABLE user1(
user_id INT,
name VARCHAR(20),
email VARCHAR(30),
age INT,
rdate DATE
);
DESC user1;
# 제약조건이 있는 테이블 생성
CREATE TABLE user2(
user_id INT PRIMARY KEY AUTO_INCREMENT,
name VARCHAR(20) NOT NULL,
email VARCHAR(30) NOT NULL UNIQUE,
age INT DEFAULT 30, -- NULL값을 넣고 싶으면 일부러 넣어줘야지 안넣으면 30이 됨
rdate TIMESTAMP
);
DESC user2;
SELECT NOW(); -- 현재 날짜, 시간을 출력하는 함수
# ALTER : 데이터베이스나 테이블 수정할 때 사용
# 데이터베이스의 인코딩 방식 수정
SHOW VARIABLES LIKE "character_set_database";
ALTER DATABASE test CHARACTER SET = ascii;
ALTER DATABASE test CHARACTER SET = utf8mb4;
# 테이블 데이터 수정
# ADD, MOTIFY, DROP -- 컬럼 추가 / 컬럼 속성값 변경 / 컬럼 삭제
DESC user2;
ALTER TABLE user2 ADD tmp TEXT;
ALTER TABLE user2 MODIFY COLUMN tmp int; -- 하위 호환성을 위해 COLUMN을 붙여주는 것이 좋다.
ALTER TABLE user2 DROP tmp;
# DROP
# 데이터베이스를 생성해서 삭제
CREATE DATABASE tmp;
SHOW databases;
DROP DATABASE tmp;
# 테이블을 생성 후 삭제
CREATE TABLE tmp (id int);
SHOW TABLES;
DROP TABLE tmp;
# CRUD : C(create) : INSERT
DESC user1;
INSERT INTO user1(user_id, name, email, age, rdate)
VALUE (1, "jin", "jin@gmail.com", 32, now());
INSERT INTO user1(user_id, name, email, age, rdate)
VALUES (2, "andy", "jin@gmail.com", 25, '2021-01-06')
, (3, "time", "tim@gmail.com", 55, '2018-03-18')
, (4, "peter", "peter@gmail.com", 35, '2021-10-06')
, (5, "pretty", "pretty@gmail.com", 15, '1988-04-17')
, (6, "saram", "saram@gmail.com", 20, '2015-07-17');
SELECT *
FROM user1
WHERE rdate >= "2019-01-01"; -- 날짜데이터도 연산 등이 가능하다
DESC user2;
INSERT INTO user2(name, email, age)
VALUE("flask2", "pythonGOOD2@naver.com", 25);
SELECT * FROM user2;
# SELECT된 결과 INSERT
use world;
SELECT countrycode, name, population
FROM city
WHERE population >= 900 * 10000
ORDER BY population DESC;
CREATE TABLE city_900(
countrycode CHAR(3),
name VARCHAR(20),
population INT
);
DESC city_900;
INSERT INTO city_900
SELECT countrycode, name, population
FROM city
WHERE population >= 900 * 10000
ORDER BY population DESC;
SELECT * FROM city_900;
# 한국 도시의 도시이름, 인구수를 저장하는 테이블을 생성
# 생성된 테이블에 데이터를 저장
USE world;
DESC city;
CREATE TABLE kor_city(
name VARCHAR(30), -- 가변적 길이를 가지므로 CHAR대신 VARCHAR
population INT
);
INSERT INTO kor_city
SELECT name, population
FROM city
WHERE countrycode = 'KOR'
ORDER BY population DESC;
SELECT * FROM kor_city;
# 미국에서 사용되는 언어와 해당 언어의 비율을 저장하는 테이블을 생성
#생성된 테이블에 데이터를 저장
DESC countrylanguage; -- 스키마 먼저 확인
CREATE TABLE usa_language(
language VARCHAR(30),
percentage DOUBLE -- DECIMAL(4,1)로..
);
INSERT INTO usa_language
SELECT language, percentage
FROM countrylanguage
WHERE countrycode = "USA"
ORDER BY percentage DESC;
SELECT * FROM usa_language;
#UPDATE SET
use test;
SELECT * FROM user1;
# jin 이름을 가지고 있는 사람의 나이를 20으로 변경
UPDATE user1
SET age = 20
WHERE name = "jin"
LIMIT 1; -- UPDATE, DELETE데이터는 안전장치....
use test;
SELECT * FROM user1;
# 쿼리 프로세스 확인
show processlist;
kill 11; -- 실행되는 id값 입력하면 강제중지할 수 있음. 예를 들어 UPDATE/DELETE 실수 등을 하면 이렇게 강제중지!
# 나이가 30세 이하인 경우 나이를 모두 21세로 변경하고, 현재 날짜로 변경하세요.
SELECT * FROM user1;
UPDATE user1
SET age = 21, rdate = now()
WHERE age <= 30
LIMIT 4;
SELECT version(); #MYSQL 버전 확인
# DELETE : 데이터 삭제
SELECT * FROM user1;
# 이름의 가장 앞글자가 j로 시작하는 데이터 삭제
DELETE FROM user1
WHERE name like 'j%'
LIMIT 5;
# TRUNCATE : 테이블의 스키마를 남기고 모든 데이터를 삭제 (테이블 초기화) -- AUTO_INCREMENT도 초기화됨
TRUNCATE user1;
SELECT * FROM user1;
# CRUD : INSERT, SELECT, UPDATE, DELETE
# 외래키 : FOREIGN KEY
# 데이터의 무결성을 지킬 수가 있습니다.
# ex)
# user : user_id(PK), name(VARCHAR), addr(VARCHAR)
# money : money_id(PK), income(INT), user_id(FK)
# user : user_id : 1, 2, 3
# money : user_id : 1, 2, 4(무결성 깨졌다!)
# FK : money.user_id ->(참조) user.user_id
CREATE TABLE user (
user_id INT PRIMARY KEY AUTO_INCREMENT,
name VARCHAR(20),
addr VARCHAR(20)
);
DESC user;
CREATE TABLE money(
money_id INT PRIMARY KEY AUTO_INCREMENT,
income INT,
user_id INT
);
DESC money;
INSERT INTO user(name, addr)
VALUES ("andy", "seoul"), ("po", "pusan");
SELECT * FROM user;
INSERT INTO money(income, user_id)
VALUES (1000, 1), (2000, 2); -- 아직 FK설정을 안해서 데이터 추가가 에러없이 됨
SELECT * FROM money;
TRUNCATE money;
# FK키 설정 : ALTER
ALTER TABLE money
ADD CONSTRAINT fk_user
FOREIGN KEY (user_id)
REFERENCES user (user_id);
DESC money;
# FK키 설정 : CREATE TABLE
DROP TABLE money;
CREATE TABLE money(
money_id INT PRIMARY KEY AUTO_INCREMENT,
income INT,
user_id INT,
FOREIGN KEY (user_id) REFERENCES user (user_id)
);
DESC money;
INSERT INTO money(income, user_id)
VALUES (1000, 1), (2000, 2);
SELECT * FROM money;
# money.user_id(1,2) -> user.user_id(1,2)
# 참조 당하고 있는 데이터를 삭제하기 : 삭제 X
SELECT * FROM user;
DELETE FROM user
WHERE name = "po"
LIMIT 1;
# ON UPDATE, ON DELETE 설정
# ACTION
# CASCADE : 삭제하거나 수정하면 참조하는 데이터도 삭제하거나 수정
# SET NULL : 삭제하거나 수정하면 참조하는 데이터는 NULL 데이터로 변경
# NO ACTION : 삭제하거나 수정하면 참조하는 데이터는 변경 x
# SET DEFAULT : 삭제하거나 수정하면 참조하는 데이터는 DAFAULT 값으로 변경
# RESTRICT : 참조하는 데이터는 삭제하거나 수정할 수 없음
DROP TABLE money;
CREATE TABLE money(
money_id INT PRIMARY KEY AUTO_INCREMENT,
income INT,
user_id INT,
FOREIGN KEY (user_id) REFERENCES user (user_id)
ON UPDATE CASCADE ON DELETE SET NULL
);
INSERT INTO money(income, user_id)
VALUES (1000, 1), (2000, 2);
SELECT * FROM money;
SELECT * FROM user;
UPDATE user
SET user_id = 3
WHERE user_id = 2
LIMIT 1;
DELETE FROM user
WHERE user_id = 3
LIMIT 1;
# FUNCTIONS
# CEIL(올림), ROUND(반올림), TRUNCATE(버림), CONCAT, COUNT
SELECT CEIL(12.345); -- 소수 몇 째짜리 올림은 원래 안되나 편법적으로
SELECT CEIL(12.345 * 100) / 100; -- 이렇게 쓸 수는 있음
SELECT ROUND(12.345, 2);
SELECT TRUNCATE(12.345, 2);
# DATE_FORMAT
USE sakila;
# payment_date에서 "년-월" 포맷으로 유니크한 데이터를 출력
SELECT DISTINCT(DATE_FORMAT(payment_date, "%Y-%m"))
FROM payment;
# CONCAT : 합치다
USE world;
SELECT name, indepyear, CONCAT(name, "(", indepyear, ")")
FROM country
WHERE indepyear != "null";
# COUNT : 데이터 갯수를 출력
# city의 전체 수를 출력하세요.
SELECT count(*)
FROM city;
# 총 대륙의 갯수를 출력하세요.
SELECT COUNT(DISTINCT(continent))
FROM country;
# 전세계 언어의 개수를 출력하세요.
SELECT COUNT(DISTINCT(language)) AS total_language_count
FROM countrylanguage;
# 조건문 : IF, IFNULL, CASE WHEN THEN ELSE -- 조건이 한 가지일땐 IF
# 도시의 인구가 500만 이상이면 "big", 500만 미만이면 "small"를 출력하는 컬럼을 추가
SELECT countrycode, name, population
, IF(population >= 500 * 10000, "big", "small") AS scale
FROM city
ORDER BY population DESC;
SELECT name, indepyear, IFNULL(indepyear, 0)
FROM country;
#국가별로 인구가 1억이상 "big", 5000만 이상 "medium", 5000만 이하 "small"
SELECT name, population,
CASE
WHEN population >= 10000 * 10000 THEN "big"
WHEN population >= 5000 * 10000 THEN "medium"
ELSE "small"
END AS scale
FROM country
ORDER BY population DESC;
# GROUP BY
# 여러개의 동일한 데이터를 가지는 특정 컬럼을 기준으로 row 데이터를 합쳐주는 기능을 수행
# 합쳐지는 다른 컬럼을 aggregation 해주는 기능 : DISTINCT랑 다름
# COUNT, MAX, MIN, AVG, SUM 등등
# COUNT
# 대륙별 국가의 갯수를 출력하세요.
# continent 컬럼을 기준으로 row 데이터를 합쳐줌
# 합쳐진 데이터의 갯수를 세서 새로운 컬럼으로 출력
SELECT continent, count(continent) AS continent_count
FROM country
GROUP BY continent;
# 대륙별로 인구수가 가장 많은 국가 인구수, GNP 가장 많은 국가의 GNP 출력
SELECT continent, MAX(population), MAX(gnp)
FROM country
GROUP BY continent;
# 대륙별로 전체 인구수, 전체 GNP, 1인당 GNP 출력
SELECT continent, SUM(population), SUM(gnp), SUM(gnp) / SUM(population) AS gpp
FROM country
WHERE gnp != 0 AND population != 0
GROUP BY continent
ORDER BY gpp DESC;
#sakila payment테이블에서 스태프별 발생시킨 총 매출액을 출력하여 어떤 스태프가 더 매출을 높게 올렸는지 확인
USE sakila;
SELECT staff_id, sum(amount) AS total_amount
FROM payment
GROUP BY staff_id
ORDER BY amount DESC;
# HAVING
# 대륙별 전체 인구를 출력하고, 대륙 전체의 인구가 5억 이상인 대륙만 조회
USE world;
SELECT continent, SUM(population) AS population
FROM country
GROUP BY continent
HAVING population >= 50000 * 10000; -- WHERE절과의 차이, HAVING은 GROUP BY 후에 조건임
# WITH ROLLUP
# 여러개의 컬럼을 GROUP BY하고 각 컬럼의 데이터별로 총합을 row에 출력하는 방법
USE sakila;
SELECT IFNULL(customer_id, "total") AS costomer_id
, IFNULL(staff_id, "total") AS staff_id, SUM(amount) AS amount
FROM payment
GROUP BY customer_id, staff_id
WITH ROLLUP;
# world 데이터 베이스의 country 테이블에서 대륙별 지역별 전체 인구수와 대륙에 대한 전체 인구수를 출력
USE world;
SELECT IFNULL(continent, "total") AS continent
,IFNULL(region, "total") AS region
, sum(population) AS total_population
FROM country
GROUP BY continent, region
WITH ROLLUP;
#변수선언
SET @data = 1;
SELECT @data;
#도시인구수가 많은 도시 1위~3위까지 출력 데이터를 컬럼을 만들어서 출력 cf.오라클 - RANK함수 있음
SET @RANK = 0;
SELECT @RANK := @RANK + 1 AS 'rank', name, population -- := (row데이터가 하나 출력될 때마다)
FROM city
ORDER BY population DESC
LIMIT 3;
SELECT @rank;
# 데이터 타입의 형변환 : CAST, CONVERT
# 실수 데이터 타입을 정수로 변환해서 출력
SELECT name, gnp, CAST(gnp AS SIGNED INTEGER)
FROM country;
#Quiz 1. 국가 코드별 도시의 갯수를 출력하세요. (상위 5개를 출력)
SET @RANK = 0;
SELECT @RANK := @RANK + 1 AS 'rank', countrycode, count(*) AS count
FROM city
GROUP BY countrycode -- RANK는 이미 매겨진 상태에서 GROUP BY를 하기 때문에 RANK정보가 꼬이는 것--> 서브쿼리로 해결해야 함
ORDER BY count DESC
LIMIT 5;
# +rank 적용
#Quiz 2. 대륙별 몇개의 국가가 있는지 대륙별 국가의 갯수로 내림차순하여 출력하세요.
SELECT continent, count(*) AS count
FROM country
GROUP BY continent
ORDER BY count DESC;
#Quiz 3. 대륙별 인구가 1000만명 이상인 국가의 수와 GNP의 평균을 소수 둘째 자리에서 반올림하여 첫째자리까지 출력하세요.
SELECT continent, count(*) AS count, ROUND(avg(gnp), 1) AS avg_gnp
FROM country
WHERE population >= 1000 * 10000
GROUP BY continent
ORDER BY avg_gnp DESC;
select * from country;
# Quiz 6. countrylanguage 테이블에서 언어별 20개 국가 이상에서 사용되는 언어를 조회하고 언어별 사용되는 국가수에 따라 내림차순하세요.
SELECT language, count(*) AS count
FROM countrylanguage
GROUP BY language
HAVING count >= 20 -- GROUP BY를 한 후의 조건이므로 HAVING을 쓴다!
ORDER BY count DESC;
#Quiz 8. World 데이터 베이스의 countrylanguage에서 언어의 사용 비율이 90%대(90 ~99.9)의 사용율을 갖는 언어의 갯수를 출력하세요.
#WHERE절에서도 FUNCTION 사용이 가능
SELECT count(distinct(language))
FROM countrylanguage
WHERE percentage BETWEEN 90 AND 99.9;
SELECT count(distinct(language))
FROM countrylanguage
WHERE TRUNCATE(percentage * 0.1, 0) * 10 = 90;
#Quiz 9. 1800년대에 독립한 국가의 수와 1900년대에 독립한 국가의수를 출력하세요.
# CASE WHEN THEN
SELECT count(indepyear) AS count,
CASE
WHEN indepyear >= 1900 THEN 1900
WHEN indepyear >= 1800 THEN 1800
ELSE 0
END AS ipa
FROM country
WHERE indepyear >= 1800
GROUP BY ipa;
-- HAVING ipa IN (1800, 1900);
-- HAVING ipa > 0;
#Quiz 10. sakila의 payment 테이블에서 월별 총 수입을 출력하세요.
USE sakila;
SELECT date_format(payment_date,"%Y-%m") AS monthly, sum(amount) AS amount
FROM payment
GROUP BY monthly;
#Quiz 12. film_list 뷰에서 카테고리별 가장 많은 매출을 올린 카테고리 3개를 매출순으로 정렬하여 아래와 같이 출력하세요.
SELECT category, SUM(price) AS price2
FROM film_list
GROUP BY category
ORDER BY price2 DESC
LIMIT 3;
SELECT category
FROM film_list
GROUP BY category
ORDER BY SUM(price) DESC
LIMIT 3;'Python활용 빅데이터전문가과정' 카테고리의 다른 글
| 210111 MON - 파이썬 기본문법 (2) (0) | 2021.01.13 |
|---|---|
| 210108 FRI 수업 - 파이썬 기본문법(1) (0) | 2021.01.10 |
| 210107 THU 수업 - MySQL문법(3) (0) | 2021.01.07 |
| 210105 TUE 수업 - MySQL 문법(1) (0) | 2021.01.05 |
| 210104 MON 수업 (0) | 2021.01.04 |


