
Super Coding Addict
210108 FRI 수업 - 파이썬 기본문법(1) 본문
* 아나콘다 설치
- 64bit : 데이터 분석이 목적
- 32bit : 유가증권시장에서 자동트레이딩이 목적일 때 등
* 1GB = 1024MB = 1024*1024KB = 1024*1024*1024B = 8*1024*1024*1024bits
* 하드디스크와 메모리
- 하드디스크 : 저장장치 [비휘발성]
- 메모리 : 임시저장소 [휘발성]
* 데이터 타입
- 문자, 숫자(정수/실수)
- 숫자연산 : +, -, *(곱하기), /(나누기), //(몫), %(나머지), **(제곱)
- 문자열은 "" 또는 '' 안에 넣어준다. 두 종류의 따옴표를 사용하는 이유는, 문장 중간에 " 또는 '가 들어갔을 때 이를 문자열이 끝나는 지점이 아닌, 문자열에 포함되는 문자임을 표현하기 위해서이다.
ex) "I'm a boy" --> 여기서 '는 문자열에 포함된다
ex) '철수가 말했다. "나는 파이썬 공부중이야."'
- 문자형 데이터의 덧셈은 문자열을 이어 붙여준다
ex) print("안녕" + "하세요")의 결과는 '안녕하세요'
ex) print("3" + "4")의 결과는? 7이 아니라, 34이다.
- 문자형 데이터에 숫자를 곱하면? 곱한 숫자만큼 문자열을 반복!
ex) print("안녕" * 3)의 결과는 '안녕안녕안녕'
* 변수
- 변수는 상황에 따라 변하는 값을 저장하는 공간
- 파이썬 인터프리터는 등호를 만나면 우변을 먼저 해석하고, 우변의 값을 좌변에 저장한다 --> 대입한다의 의미!
- 변수명으로는 영문(한글), 숫자, _(언더스코어) 사용 O / 대소문자 구분 O / 이름 첫글자는 숫자 X / 예약어(print, def 등)은 되도록 쓰지 말자.
- cf. \은 파이썬에서 특수기호
: 가령 문자열안에 포함된 ", ' 등의 특수한 기능을 하는 문자를 문자열 자체로 인식시키려면 \뒤에 붙여주면 된다.
: \n은 줄바꿈, \t은 탭만큼 띄워줌
* 인덱싱
- 문자열 생성시 자동으로 인덱스가 부여된다
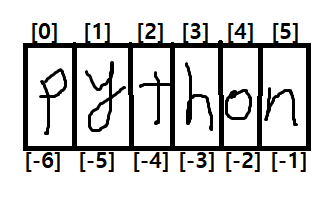
- 인덱스는 0부터 시작하여 한글자씩 부여된다. 왼쪽에서 오른쪽으로 가면서 +1
- 반대로 맨 오른쪽 글자로부터 왼쪽으로는 -1
* 슬라이싱의 개념 cf.인덱스

- 슬라이싱 : 문자열에서 하나 이상의 데이터를 가져오는 것
- 슬라이싱은 인덱스와 달리 범위를 지정해야하므로 문자사이에 인덱스가 위치한다.
ex) 위의 그림에서 [0:2]의 범위로 슬라이싱하면 삼성전자 LG전자가 선택된다.
#예제
string = "hello world"
print(string[0 : 5]) # 결과 : hello
print(string[0 : -6]) #결과 : hello
print(string[ : ]) #결과 : hello world
#문자열을 건너뛰며 슬라이싱도 가능하다
print(string[ : : 2] #결과 : hlowrd
처음부터 끝까지 슬라이싱을 하되, 2칸 간격으로 슬라이싱
#문자열 뒤집기
print(string[ : : -1]) #결과: dlrow olleh
증감폭을 -1로 하면 거꾸로 슬라이싱
* 문자열 응용
- 생성된 문자열은 수정이 불가하다.
ex) string = "abc"
string[0] = "A" 은 불가능하다.
만약 Abc라고 출력하고 싶다면, 'A' + string[1 : ]으로 따로 출력한 결과값을 더해줘야 한다.
- multi-line 문자열
print("안녕하세요\n만나서반갑습니다\n파이썬공부중입니다")
#이렇게 쓸 수도 있지만,
print("""안녕하세요
만나서반갑습니다
파이썬공부중입니다""")
#이렇게 """을 활용하면 줄을 띄우면 \n을 자동으로 처리해준다.
"""대신 '''을 쓸 수도 있다.
"엄청나게 긴 문장을 줄을 띄우지 않고 계속 이어서 쓰고 싶지만, 이렇게 화면을 넘어갈 정도로 문장이 길어진다면 보기가 싫죠"
#이런식으로 문장이 길어질 때 실제 줄을 띄우는 게 아니지만 코드상에서 가독성을 높여주기 위해
"엄청나게 긴 문장을 줄을 띄우지 않고 계속 이어서 쓰고 싶지만,"\
"이렇게 화면을 넘어갈 정도로 문장이 길어진다면 보기가 싫죠"
이렇게 \를 활용하면 코드상에선 줄바꿈이 된 것처럼 가독성은 높아지는 한편 한 문장으로 이어쓸 수 있다.
- 문자열 formatting
: print(f"{변수}를 따로 출력하기)
이렇게 문자열 정의 기호 앞에 f를 붙이고, 변수명은 {}안에 넣어준다.
매번 변수의 값이 바뀌는 경우 {}안에 변수명을 넣어주면, 바뀐 변수값을 그대로 출력해주는 편의성이 있다.
가격 = 100
print(f"이 물건의 가격은 {가격}원 입니다")
#결과값 : 이 물건의 가격은 100원 입니다.
cf. 물론 따로 formatting을 하지 않고, 콤마로 문자열따로 변수따로 구분하여 써줄 수 있지만
이러한 구분자를 쓰면 구분자 뒤에 스페이스가 한칸 들어가기 때문에 원하지 않는 공백을 가지게 된다.
#이 때 가격+100등 연산을 {}안에서 하는 것도 가능하다.
print(f"이 물건의 가격은 {가격 + 100}원 입니다")
#결과값 : 이 물건의 가격은 200원 입니다.- 문자열과 메서드
### 문자열 치환 : replace
number = "010-1234-5678"
print(number.replce('-', ''))
#문자열 안에서 -를 찾아 공백으로 바꾸어준다
#결과값 : 01012345678
### 문자열 길이 반환 : len
len(변수)
### 대소문자 변환 : upper, lower
변수.upper()
변수.lower()
### 양쪽 / 왼쪽 / 오른쪽 공백제거 : strip, lstrip, rstrip
변수.strip()
# 이 때, 특정 문자 제거도 가능하다
변수 = "특정문자 제거하기 ,."
print(변수.rstrip(',.')) #결과값 : "특정문자 제거하기"
### 문자열 가운데/왼쪽/오른쪽 정렬하기 : center/ljust/rjust
변수 = "안녕"
print(변수.center(30))
#결과값은 30자에서 변수의 글자수를 뺀 나머지를 공백으로 채워 문자열을 정가운데로 정렬
### 문자열 채우기(0으로) : zfill
변수 = "안녕"
print(변수.zfill(10))
#결과값은 10자에서 변수의 글자수를 뺀 나머지의 글자수를 0으로 채워,
00000000안녕
### 문자열 위치 찾기 : index/rindex
변수 = "안녕하세요"
print(변수.index("하")) #결과값 : 2
#'하' 근처에 있는 두 개의 문자 출력하기
idx = 변수.index("하")
print(변수[idx-1], 변수[idx+1]) #결과값 : 녕 세
#같은 문자열이 여러개가 있을 때, ridex를 쓰면 왼쪽이 아니라 맨오른쪽부터 찾아준다.
변수 = "안녕하세요세하녕안"
변수.ridex("안") = 8
### 문자열 개수 세기 : count
print(변수.count('안')) #결과값: 2
* 참고 : 메모리와 변수
- 변수에 값을 저장한다? 약간의 어폐가 있다.
- 변수에 값이 직접 저장되는 것이 아니라, 메모리상에 있는 값을 이 변수가 참조하고 있는 것이다.
* 비트
- 정보를 표현하는 최소한의 단위
- 8비트 = 1바이트
* 음수 표현방법
- MSB 사용 : 부호비트를 MSB에 추가하여 양수와 음수를 구분, 양수(0) / 음수(1)
: ex) 4비트 system
제일 왼쪽 1비트는 부호비트, 나머지는 값을 나타내는 비트
: 그러나, 100과 000이 같은 0을 나타내므로 두 개의 0이 존재한다는 문제점
: 컴퓨터의 입장에서 이렇게 부호가 다른 두 수 덧셈이 어려움
- 2의 보수 사용 : 2의 제곱수에서 특정한 값을 빼 얻은 이진수
ex) 5비트 system에서 16 - 5 계산하기
먼저 -5를 2의 보수로 나타내보자.
연산식에서 가장 큰 수보다 한 자리 수 많은 수를 제곱수로 사용하므로,
여기서는 16이 가장 큰 수이고, 16을 나타낼 수 있는 5비트보다 1비트 더 많은 6비트를 제곱수로 사용한다.
100000 -- 제곱수 (5+1bit)
- 101
------------
11011
따라서 16 -5 = 10000 + 11011 = 101011
현재 5비트 system이니 최상위 비트를 제거하면 01011이고, 이는 10진수로 나타내면 1+2+8 = 11이다.
: 2의 보수 빠르게 구하기 - 0을 1로 바뀐 뒤, 제일 마지막에 +1을 해준다!
* 최댓값, 최솟값
- 양수만 사용 : 0부터 2^n-1까지 표현 가능
- MSB 사용 : -2^(n-1) -1 부터 2^(n-1) -1까지 표현 가능
- 2의 보수 사용: -2^(n-1)부터 2^(n-1) -1까지 표현 가능
* 리스트
- 순서가 있는 자료 구조
- 대괄호[ ]로 정의
- 데이터 타입에 상관없이 값을 넣을 수 있음
### append : 값 추가
삼성전자 = [ 1200, 1500, 1800 ]
삼성전자.append[2300]
print(삼성전자) #결과값 : [1200, 1500, 1800, 2300]
### insert : 특정 위치에 값 추가 (슬라이싱과 같은 매핑방식)
print(삼성전자.insert(1, 1000)) #결과값 : [1200, 1000, 1500, 1800, 2300]
### 리스트 덧셈 : 두 개의 리스트 하나로 합치기
list1 = ['가', '나']
list2 = ['다', '라']
print(list 1 + list 2) #결과값 : ['가', '나', '다', '라']
### 리스트 곱셈 : 데이터 반복
list1 = ['가', '나', '다']
print(list1 *3) #결과값: ['가', '나', '다', '가', '나', '다', '가', '나', '다']
### 리스트 인덱싱, 슬라이싱
문자열과 같은 방법
### 리스트 값 수정 : 문자열과 달리 가능하다
list1 = ['가', '나', '다']
list1[0] = '라'
print(list1) #결과값 : ['가', '나', '다', '라']
### remove메서드 : 삭제할 값 입력받아 리스트에서 제거
list1 = ['가', '나', '다']
list1.remove('가')
### pop메서드 : 인덱스 입력받아 리스트에서 제거
list1 = ['가', '나', '다']
pop1 = list1.pop[0] #'가'를 pop1에 입력 후 list1에서 제거
### del 키워드로 제거도 가능
list1 = ['가', '나', '다']
del list1[0]
del list1[0:2] #슬라이싱도 가능
### clear메서드 : 모든 데이터 제거
list1 = ['가', '나', '다']
list.clear()
### 연습문제
list = ['a', 'b', 'c', 'd']
# 리스트에서 'c', 'd' 제거하기
new_list = list[0:2]
또는
del list[2:4]
또는
list.pop(-1)
list.pop(-1)
### index메서드 : 위치찾기
문자열과 마찬가지
### 연습문제
리스트에는 집주소로 정렬된 거주인원의 이름이 저장돼 있습니다.
neighbor = ['모세', '바울', '스데반', '마가', '마리아', '솔로몬']
하나의 이름을 입력받아 인접한 두 이웃 이름 출력하기
name = input("이름: ")
--> 스데반을 입력받았다고 가정
idx = neighbor.index(name) #idx = 2
print(f "주변에는 {neighbor[idx-1]}와 {neighbor[idx+1]}이 살고 있습니다.")
### sort메서드 : 순차정렬
### reverse메서드 : 거꾸로 정렬
### count메서드 : 개수 세기
### join 연산자 : 구분자를 기준으로 리스트 안의 모든 문자열 데이터를 연결
list = ['101호', '102호', '103호', '104호', '105호', '106호', '107호']
print("/".join(리스트)) #결과값 : '101호/102호/103호/104호/105호/106호/107호'
### split : 문자열 쪼개기
phone_number = "010-1234-5678"
phone = phone_number.split('-'));
# ''안에 있는 문자를 기준으로 문자열들을 쪼개 하나씩 리스트에 차례대로 값으로 넣어준다
print(phone) #결과값 : [010, 1234, 5678]
### 이차원 데이터 : 가로축과 세로축이 있는 데이터
list = [ [ "가", "나" ], ["다", "라" ] ]
print(type(list[0])) #list
print(list[0][1]) # '나'
# 시각적으로 보기 좋게 표현
list = [
[ "가", "나" ]
, ["다", "라" ]
]
* 참조 : 문자열과 달리 list에서 데이터 변경이 가능한 이유
- 리스트의 값들은 리스트에 직접 저장되어 있는 게 아니라, 메모리상의 값을 각각 참조하고 있는 것임
- 따라서 특정 인덱스의 값을 지운다면 그 연결고리를 끊어주게 되고, 새로운 값을 그 인덱스자리에 추가하면 새로운 값을 참조하게 되므로 문자열과 달리 데이터 변경이 가능하다
* 튜플
- 순서가 있는 자료구조 -> 인덱스 사용가능
- 소괄호( )를 사용해 정의
cf. 정수값을 튜플로 저장할 때 주의
# 숫자 1 이 저장된 튜플을 생성
tuple = (1)
print(tuple) # (1)
# 튜플이 사실 생성된 게 아니다!!!
# 하나의 정수값으로 인식함
print(type(tuple)) #int
# 따라서, tuple = (1, ) 으로 생성해야 한다.- 정의된 데이터 수정불가 -- 리스트보다 메모리는 적게 사용하면서 인덱싱 속도가 빠르다
- 인덱싱, 슬라이싱은 리스트와 동일
- 튜플은 ( )를 써주지 않아도 값을 저장되나 명시적으로 쓰는 게 좋다.
#튜플 packing
tuple = "a", "b", "c", "d"
print(tuple) # ("a", "b", "c", "d")
#튜플 unpaking
q, w, e, r = tuple- 리스트와 대부분 유사한 메서드 기능
*딕셔너리
- 연관된 데이터 저장하기에 좋은 자료구조
- key : value의 구조
- 중괄호 { } 로 묶어준다
icecream = {'메로나' : 1000, '폴라포' : 1200, '빵빠레' : 1800}# 값으로 리스트 형태도 가능
inventory = {'메로나' : [300, 20], '비비빅' : [400, 3], '죠스바' : [250,100]}- 순서가 없는 자료구조이기 때문에 인덱싱 사용 불가, 대신 키값으로 접근
icecream = {'메로나' : 1000, '폴라포' : 1200, '빵빠레' : 1800}
#메로나 가격 출력하기
print(icecream['메로나'])- append나 insert 메서드 X -> 명시적으로 key와 value 사용하여 코드 작성
icecream = {'메로나' : 1000, '폴라포' : 1200, '빵빠레' : 1800}
# '월드콘' 1500원 추가하기
icecream['월드콘'] = 1500- update 메서드로 딕셔너리를 합치거나, 키-값을 추가할 수도 있다
icecream = {'메로나' : 1000, '폴라포' : 1200, '빵빠레' : 1800}
icecream2 = {'월드콘' : 1500, '뽕따' : 700}
#icecream에 icecream2에 있는 데이터 추가
icecream.update(월드콘 = 1500, 뽕따 = 700)
또는
icecream.update(icecream2)
- del 키워드로 데이터 삭제
- pop 메서드 : key를 입력받아 그 값을 반환하고 딕셔너리에서 삭제
- popitem 메서드 : 가장 마지막에 저장된 key-value를 튜플로 반환
- clear 메서드
- keys메서드 / values메서드 : key값들만 가져오기 / value값들만 가져오기 -- 리스트형태로 저장
icecream = {'탱크보이': 1200, '폴라포': 1200, '빵빠레': 1800, '월드콘': 1500, '메로나': 1000}
print(icecream.keys())
print(icecream.values())
#결과값
dict_keys(['탱크보이', '폴라포', '빵빠레', '월드콘', '메로나'])
dict_values([1200, 1200, 1800, 1500, 1000])
#결과값이므로 리스트의 값들을 연산도 가능하다
#icecream 가격 모두 더하기
print(sum(icecream.values()))
- items메서드 : key와 value쌍 가져오기
- 리스트 안에 딕셔너리
list = [{"새우깡" : 500, "양파링" : 300}, {"비비빅" : 300}]
print(list[0]['양파링']) #결과값: 300
# 비비빅의 가격을 500으로 변경하기
list[1]['비비빅'] = 500'Python활용 빅데이터전문가과정' 카테고리의 다른 글
| 210112 TUE - 파이썬 기본문법 (3) (0) | 2021.01.15 |
|---|---|
| 210111 MON - 파이썬 기본문법 (2) (0) | 2021.01.13 |
| 210107 THU 수업 - MySQL문법(3) (0) | 2021.01.07 |
| 210106 WED 수업 - MySQL 문법(2) (0) | 2021.01.06 |
| 210105 TUE 수업 - MySQL 문법(1) (0) | 2021.01.05 |

