
Super Coding Addict
210107 THU 수업 - MySQL문법(3) 본문
* JOIN
- 같은 데이터베이스 내에서만 가능, 여러 개의 테이블에서 데이터를 모아 보여줄 때 사용



- INNER JOIN
: 공통되는 부분 출력-> 1,2 출력
- LEFT JOIN
: 1,2,3 출력
- RIGHT JOIN
: 1,2,4,5출력
- OUTER JOIN : UNION을 이용해서 할 수 있음 (LEFT JOIN 결과 UNION RIGHT JOIN 결과)
: 모든 데이터를 결과로 출력 ->1,2,3,4,5 출력
* Sub-Query
- 대부분의 쿼리문 안에 들어갈 수 있음
- 쿼리문의 효율성 예제
Case 1.
select city.countrycode, country.name as country_name
, city.name as city_name, city.population
from city
join country
on city.countrycode = country.code
having city.population >= 800 * 10000
order by city.population desc;Case 2(FROM절에 Sub-Query사용).
select sub_city.countrycode, country.name as country_name
, sub_city.name as city_name, sub_city.population
from
(select countrycode, name, population
from city
where population >= 800 * 10000) as sub_city
join country
on sub_city.countrycode = country.code
order by sub_city.population desc;- 이 두 개 쿼리문의 결과는 같다.
- 그러나 Case2가 SQL의 입장에서 더 부담이 적으므로 빠르고 효율적으로 쿼리문들을 처리하여 결과를 내어준다.
case1에서는 from city에서 city의 모든 row들을 가져오는 한편,
case2에서는 city에서 조건이 (도시의) 인구수가 800만 이상인 도시들의 정보만 가져와 이미 1차로 걸어내었기에
SQL입장에서 처리해야 하는 데이터 양이 적어지기 때문이다.
* VIEW
- 마치 가상의 테이블처럼 사용
- 실제 데이터를 가지고 있는 게 아니라 주소값으로 데이터를 참조
- 자주 사용하는 쿼리를 view로 만들어 참조함으로써 효율적으로 사용가능
- CREATE VIEW (뷰이름) AS
(뷰로 저장할 데이터를 불러오는 쿼리문)
* Data Import하기
cf. Open SQL Script

- 이렇게 workbench 상단에서 [File] - [Open SQL Script]으로 직접 SQL Script를 열 수도 있으나, 데이터가 큰 경우 이렇게 하기보단 직접 파일을 import 해줘야한다.
그렇다면, 데이터를 Import해보자.

- 불러온 data를 넣을 database를 생성한다 (create database db명;)
- show databases; 를 하면, 존재하는 데이터베이스들을 모두 확인가능하며, employees를 db가 잘 생성되었음을 알 수 있다.
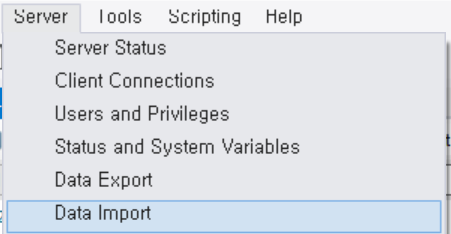
- workbench 상단에서 [Server] - [Data Import]를 클릭한다.

- 1에서 import from self-contained file을 선택하고, ... (browse) 버튼을 눌러 import할 데이터의 디렉토리를 지정한다.
- 2에서 아까 만들어놓은 db를 선택(나는 employees를 만들었다)한다.
- 3으로 표시해놓은 Import progress 탭을 클릭한다

- Start Import버튼을 누르면 Import is running...이라는 메시지가 진행되면서 import를 시작한다.

- Import Completed 메시지가 뜨면 import가 완료된 것이다.

- 다시 작업 창으로 들어와 use employees;를 쳐서 employees를 db를 선택한다.
- show tables;를 하면 employees db에 저장되어 있는 테이블들을 볼 수 있으며, 아까 import가 잘 되어서 salaries테이블이 잘 들어와 있음을 알 수 있다.
* INDEX
- 인덱스의 종류
: 클러스터형 : 검색속도 빠르게 해주는 기능이 아니라, 정렬을 해주는 기능 (ex- salary가 인덱스라면 오름차순으로 소팅)
: 보조(secondary)형 : 검색속도 빨라짐
- 데이터가 많은 테이블에서 데이터조회시 속도를 향상시킬 수 있는 방법이나 워크벤치상에서는 속도가 들쭉날쭉해서 객관적인 측정은 오늘 힘드므로 실습만!
cf. EXPLAIN (실행계획) : 쿼리를 실행할 때 어떻게 내부적으로 실행되는 지를 확인
explain select * from salaries where from_date <= "1986-01-01";- index 생성과 삭제
create index fdate on salaries (from_date);
create index tdate on salaries (to_date);- index는 다음과 같이 생성한다.
- salaries라는 테이블의 from_date(또는 to_date)라는 컬럼에 fdate(또는 tdate)라는 인덱스를 만든다는 의미
drop index fdate on salaries;
drop index tdate on salaries;- index 삭제는 다음과 같이 drop 명령어를 사용한다.
* TRIGGER
- 어떤 특정 SQL쿼리문이 수행이 될 때 (DELETE나 INSERT와 같은 이벤트) 하기 전 미리 다른 테이블에 백업을 따로 해놓고 수행을 함 (특정 테이블을 감시하고 있다가 설정한 조건이 감지되면 지정해 놓은 쿼리가 실행되도록 하는 방법)
트리거를 실습해보자.

- 트리거 실행시 백업데이터를 저장할 db를 만들고 이를 선택한다.


- 트리거를 설정할 테이블인 chat과 트리거 실행시 백업데이터를 저장할 backup 테이블을 생성한다.
- 이때 backup_date 컬럼의 데이터타입은 timestamp인데, default값으로 현재 날짜, 시간을 설정하는 currunt_timestamp 예약어를 사용했다.
- 트리거 설정은 다음과 같이 한다.
- CREATE TRIGGER trigger_name
{BEFORE | AFTER} {INSERT | UPDATE| DELETE }
ON table_name FOR EACH ROW
BEGIN
trigger_body;
END;
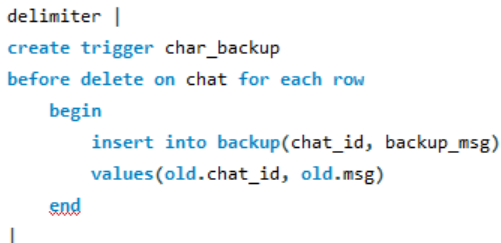
- char_backup trigger를 생성한다.
- 여기서는 chat테이블에 대해 delete 이벤트가 발생하면 delete를 하기 전 이 trigger가 작동해 백업을 하게 된다.
- begin end 사이에 들어간 trigger body 또한 쿼리문으로 이루어져 있는데 여기서 ;를 하면 trigger가 끝난 end 이후에도 ;를 찍어주고 2번의 ;가 들어가기 때문에 delimiter를 써준다.
- delimiter를 쓰면, | | 사이를 모두 하나의 쿼리로 인식한다.
--> 왜인지는 모르겠는데, delimiter가 잘 안먹히는 건지 이 이후에 쿼리문 실행이 꼬여 쿼리문 하나가 여러번 동작하는 등 이상한 일이 벌어졌다... 그래서 delimiter 부분을 드래그하여 그 부분만 실행시킨 다음 이 트리거 구문을 지우고 그 다음 쿼리들을 작성했다.

- chat 테이블에 데이터를 추가해준다.

- 아까 설정한 트리거를 발생시키는 이벤트인 chat 테이블에서 delete를 실행한다.

- 트리거가 동작하여 backup 테이블에 chat테이블에 백업 데이터가 잘 저장되었음을 확인할 수 있다.
* BACKUP
- Hot Backup
: 데이터 베이스 중지 하지 않은 상태로 데이터 백업
: 백업하는 동안 데이터가 변경되어 동기화가 깨질 수도 있음
- Cold Backup
: 동작 중지시키고 안정적으로 백업
: 그러나 백업을 하는 동안 서비스운영 중단해야 함
- Logical Backup
: SQL문으로 백업
: 이진파일을 변환하는 과정이 필요하므로 속도가 느리다
: but 바이너리 파일을 가져오는 게 아니라 문자열이므로 디스크 용량 차지가 적음
: 변환과정 필요하므로 작업시 시스템 자원을 많이 사용함
: 쿼리문이 하나하나 실행하므로 에러메시지를 볼 수 있어 문제 발생에 대한 파악이 쉽다
: 서버 OS 호환이 잘됨 (SQL문이 같으니까)
- Physical Backup
: 파일 자체를 capy & paste를 하는 것임
- 보통 회사에서는 cold backup을 함
- 백업하는 데이터 크기가 매우 크지 않으면 logical backup, 데이터 용량이 크면 physical backup
- SQL형태 / CSV파일형태 (comma seperated value)
- 데이터베이스 워크벤치(workbench)에서 백업해보기 [hot logical backup 실습]

- 외부 db를 import할 때와 반대로, workbench 상단에서 [Server] - [Data Export]를 선택한다.

- 1에서 백업할 데이터베이스를 선택
- 2에서 백업 결과를 저장할 디렉토리 설정
- 3을 눌러 탭을 이동한다.

- 탭 이동후 하단의 Start Export를 클릭하면 백업을 시작한다.
자, 이제 sql이 아니라 엑셀에서 열어볼 수 있는 csv 파일로도 백업해보자.

- world 데이터베이스를 선택한 후, country테이블에서 모든 데이터를 불러왔다.

- workbench 상단에서 [Query] - [Export Results]를 선택한다.

- 백업파일을 저장할 디렉토리를 설정하고 파일이름 설정한 뒤, 파일형식을 CSV로 설정하여 저장하면 완료!

- 저장한 csv형식의 백업파일을 엑셀로 열어보면 이렇게 컬럼에 맞게 데이터들이 예쁘게 정리되어 백업되어 있음을 볼 수 있다.
* 수업 코드
# 1. 데이터 타입 : 숫자형, 문자형, 날짜시간
# 숫자형 : 정수, 실수
# 문자형 : CHAR, VARCHAR, TEXT
# 날짜시간 : 연도, 날짜, 시간, 날짜시간alter
# 2. 제약조건
# NOT NULL, UNIQUE, PRIMARY KEY, FOREIGN KEY, DEFAULT, AUTO_INCREMENT
# CURRENT TIMESTMAP
# 3. DDL : 데이터 정의어
# 데이터베이스나 테이블을 만들고 수정하고 삭제하고...
# CREATE, SHOW, ALTER, DROP
# 4. C(insert), R(read), U(update), D(delete)
# INSERT INTO, UPDATE SET, DELETE FROM
# 5. FOREIGN KEY : 외래키
# WHY USE? 테이블의 특정 컬럼이 무결성이 지켜지도록 하는 기능
# money.user_id ->(참조) user.user_id
# user.user_id가 없으면 money.user_id에 데이터가 들어올 수 없음
# ON UPDATE, ON DELETE
# 6. FUNCTIONS
# CEIL, ROUND, TRUNCATE, DATE_FORMAT, CONCAT, COUNT
# IF, IFNULL, NULLIF(특정 데이터가 NULL이 아닌 경우~), CASE WHEN THEN ELSE END
# 7. GROUP BY
# 특정 컬럼에 중복되는 데이터를 합치면서 다른 컬럼이 합쳐질때 AGG 함수를 사용해서
# row 데이터를 합치는 기능
# AGG : SUM, MIN, MAX, COUNT, GROUP_CONCAT ...
# 8. HAVING
# SELECT(3) - FROM(1) - WHERE(2) - GROUP BY(4) - HAVING(5) - ORDER BY - LIMIT 순서로 쿼리문을 쓴다
# 9. 변수선언
# set @<변수명> = <값>;
# 랭크 데이터 출력
# 10. 데이터 타입의 형변환
# CAST, CONVERT
CREATE DATABASE test3;
use test3;
CREATE TABLE user(
user_id INT PRIMARY KEY AUTO_INCREMENT,
name VARCHAR(30)
);
CREATE TABLE addr(
addr_id INT PRIMARY KEY AUTO_INCREMENT,
addr VARCHAR(30),
user_id INT
);
SHOW tables;
INSERT INTO user(name)
VALUES ("jin"), ("po"), ("alice");
SELECT * FROM user;
INSERT INTO addr(addr, user_id)
VALUES ("seoul", 1), ("pusan", 2), ("daegu", 4), ("seoul", 5);
SELECT * FROM addr;
#INNER JOIN
SELECT *
FROM user
JOIN addr;
# user : 3 * addr * 4 = 12
SELECT *
FROM user
JOIN addr -- INNER JOIN에서 INNER는 생략가능
ON user.user_id = addr.user_id; -- JOIN에서 WHERE은 ON으로.
SELECT *
FROM user, addr -- 이렇게도 쓸 수 있으나 따라서 ON대신 WHERE절을 써줘야함
WHERE user.user_id = addr.user_id;
SELECT *
FROM user, addr, addr2, addr3 --
WHERE user.user_id = addr.user_id;
#LEFT JOIN
USE test3;
SELECT user.user_id, user.name, addr.addr
FROM user
LEFT JOIN addr
ON user.user_id = addr.user_id;
#RIGHT JOIN
SELECT addr.user_id, user.name, addr.addr
FROM user
RIGHT JOIN addr
ON user.user_id = addr.user_id;
#UNION : 두 개의 쿼리 결과를 합쳐줍니다. (중복데이터는 제거)
SELECT name
FROM user
UNION
SELECT addr
FROM addr;
#UNION ALL
SELECT name
FROM user
UNION ALL
SELECT addr
FROM addr;
# LEFT JOIN과 RIGHT JOIN을 UNION으로 합쳐주면 OUTER JOIN이 된다
SELECT user.user_id, user.name, addr.addr
FROM user
LEFT JOIN addr
ON user.user_id = addr.user_id
UNION
SELECT addr.user_id, user.name, addr.addr
FROM user
RIGHT JOIN addr
ON user.user_id = addr.user_id;
#JOIN 실습
USE world;
#국가코드, 국가이름, 국가인구, 도시이름, 도시인구 출력
#국가O, 도시X : INNER JOIN
#컬럼추가 : 해당 도시가 국가에서 몇 %의 인구가 거주하는지 출력
#도시 인구가 900만 이상이 사는 도시를 도시인구수 순으로 내림차순하여 정렬 후 출력
SELECT city.countrycode
, country.name AS country_name
, city.name AS city_name
, country.population AS country_population
, city.population AS city_populatuion
, ROUND(city.population / country.population * 100, 2) AS rate
FROM city
JOIN country
ON country.code = city.countrycode
HAVING city.population >= 900 * 10000
ORDER BY city.population DESC, rate DESC;
# sakila 데이터베이스에서 payment와 staff 테이블을 JOIN하여 스테프 아이디, 스테프 전체 이름, 매출액을 출력하세요.
# CONCAT 사용
use sakila;
select staff.staff_id, concat(staff.first_name, " ", staff.last_name) as staff_name
, sum(payment.amount)
from staff
join payment
on staff.staff_id = payment.staff_id
group by staff_name;
use world;
select * from country;
# 테이블 세개 조인하기
# 국가별, 도시별, 언어의 사용율을 출력
select country.name as country_name
, city.name as city_name
, country.population as country_population
, city.population as city_population
, countrylanguage.language
, countrylanguage.percentage
from country
join city
on country.code = city.countrycode
join countrylanguage
on country.code = countrylanguage.countrycode;
#join on 구문 없이 join하기
select country.name as country_name
, city.name as city_name
, country.population as country_population
, city.population as city_population
, countrylanguage.language
, countrylanguage.percentage
from country, city, countrylanguage
where country.code = city.countrycode = countrylanguage.countrycode;
# 위의 결과에서 도시 인구기준으로 해당 언어를 사용하는 인구수 컬럼 출력
select country.name as country_name
, city.name as city_name
, countrylanguage.language
, countrylanguage.percentage
, city.population as city_population
, round((countrylanguage.percentage / 100) * city.population, 0)as language_population
from country
join city
on country.code = city.countrycode
join countrylanguage
on country.code = countrylanguage.countrycode;
#Sub-Query
#SELECT
# 1개의 row에 컬럼으로 전체 국가수, 전체 도시수, 전체 언어수를 출력
select
(select count(*) from country) as total_country,
(select count(*) from city) as total_city,
(select count(distinct(language)) from countrylanguage) as total_lang
from dual;
#위에서 나온 결과를 피봇해서 출력
select "total_country", (select count(*) from country) as count
from dual
union
select "total_city", (select count(*) from city) as count
union
select "total_language", (select count(distinct(language)) from countrylanguage) as count
from dual;
#FROM
#인구가 800만 이상이 되는 도시의 국가코드, 국가이름, 도시이름, 도시인구수 출력
# sub-query, having
# having 사용
select city.countrycode, country.name as country_name
, city.name as city_name, city.population
from city #4096
join country #239 > 4096 * 239
on city.countrycode = country.code
having city.population >= 800 * 10000
order by city.population desc;
#sub-query 사용
select sub_city.countrycode, country.name as country_name
, sub_city.name as city_name, sub_city.population
from
(select countrycode, name, population
from city
where population >= 800 * 10000) as sub_city #10
join country #239 > 10 * 239
on sub_city.countrycode = country.code
order by sub_city.population desc;
-- SQL입장에서 SQL명령을 수행시 더 빠르고 효율적으로 작업을 할 수 있을 지를 고민한다.
# WHERE
# 900만 이상의 인구가 있는 도시의 국가의 국가코드, 국가이름, 대통령이름을 출력하세요.
select code, name, headofstate
from country
where code in (
select countrycode
from city
where population >= 900 * 10000)
;
# any(or과 비슷), all(and와 비슷)
# 한국이나(OR) 브라질보다 인구수가 많은 국가코드, 국가이름, 인구수를 출력
# 한국 5000, 브라질 12000
select code, name, population
from country
where population >= all( -- any는 두 가지 조건 중 하나만 맞아도 ok, all은 모든 조건이 다 맞아야 ok
select population
from country
where code in ('KOR', 'BRA') -- 결과값이 2개
);
# 지역과 대륙별 사용하는 언어 출력
select distinct country.region, country.continent, countrylanguage.language
from country
join countrylanguage
on country.code = countrylanguage.countrycode;
# 위의 쿼리를 활용하여 지역과 대륙별 사용하는 언어의 수 출력
# GROUP BY, COUNT 함수 사용, From 절에 위의 쿼리를 활용
select sub.continent, sub.region, count(sub.language) as count
from (
select distinct country.region, country.continent, countrylanguage.language
from country
join countrylanguage
on country.code = countrylanguage.countrycode
)as sub
group by sub.region, sub.continent
order by sub.continent;
# VIEW
# 가상의 테이블
# DATA(A(1), B(2), C(3))
# VIEW(2,3)
# RAM, HDD : [A](1), [B](2), [C](3)
# DATA2 [A](4), [B](5), [C](6)
# VIEW[2, 3] -- 실제 데이터를 가지고 있는 게 아니라, 주소값을 가지고 그 데이터를 참조하는 것이다.
# WHY USE? 자주 사용하는 쿼리를 줄여줄 수 있음
# 수정 및 인덱스와 같은 설정이 불가능
# 국가코드, 국가이름, 도시이름이 있는 뷰를 생성
create view city_country as
select city.countrycode
, country.name as country_name
, city.name as city_name
from city, country
where city.countrycode = country.code;
select * from city_country;
# 국가코드, 국가이름, 도시이름, 사용언어를 출력
select city.countrycode, country.name, city.name, countrylanguage.language
from country, city, countrylanguage
where country.code = city.countrycode
and city.countrycode = countrylanguage.countrycode;
#뷰 활용
select cc.countrycode, cc.country_name, cc.city_name, countrylanguage.language
from city_country as cc, countrylanguage
where cc.countrycode = countrylanguage.countrycode;
# View 실습 문제
# step 1. 한국의 인구수보다 많은 국가의 국가코드, 국가이름, 국가 인구수, 도시이름, 도시 인구수를 출력하고 도시 인구수 순으로 정렬하여 출력
# 1. 한국의 인구수를 출력 : query1
# 2. country where > query 1 : query2
# 3. city join (query 2)
select city.countrycode, sub.name, sub.population
, city.name, city.population
from city
join (
select code, name, population
from country
where country.population >= (
select population
from country
where code = 'KOR'
)
) as sub
on city.countrycode = sub.code
order by city.population desc;
create view more_than_kor as
select code, name, population
from country
where country.population >= (
select population
from country
where code = 'KOR');
select city.countrycode, mtk.name, mtk.population
, city.name, city.population
from city
join more_than_kor as mtk
on city.countrycode = mtk.code
order by city.population desc;
# INDEX
# 저장공간이 당연히 필요
# select는 빨라지지만 insert, update, delete는 느려지는 단점
# select시 where절에 들어가는 컬럼을 index로 설정하면 좋다
# B-tree 알고리즘
create database employees;
show databases;
use employees;
show tables;
select count(*) from salaries;
select * from salaries limit 10;
#인덱스 확인
show index from salaries;
select * from salaries where from_date < "1986-01-01";
select * from salaries where to_date < "1986-01-01";
# 실행계획 : 쿼리를 실행할 때 어떻게 내부적으로 실행되는 지 확인
explain select * from salaries where from_date < "1986-01-01";
-- type:ALL 전체테이블에 대해 풀서칭을 한다는 것
-- rows와 filtred는 예측값이므로 100% 믿어선 안됨
-- 인덱스를 설정하고 나면 type이 range가 됨
explain select * from salaries where to_date < "1986-01-01";
#인덱스 생성
create index fdate on salaries (from_date);
create index tdate on salaries (to_date);
#인덱스 삭제
drop index fdate on salaries;
drop index tdate on salaries;
# 트리거 : tirgger
# 특정 테이블을 감시하고 있다가 설정한 조건이 감지되면 지정해 놓은 쿼리가 실행되도록 하는 방법
# world.city : insert, update, delete : query(insert)
create database tr;
use tr;
# table 두개 생성 : chat, backup
create table chat(
chat_id int primary key auto_increment,
msg varchar(200)
);
create table backup(
backup_id int primary key auto_increment,
chat_id int,
backup_msg varchar(200),
backup_date timestamp default current_timestamp
);
show tables;
# 트리거 생성
#delimiter 시작 - 끝 이것을 하나의 쿼리로 인식, 현재 ;가 2번으로 인식되기 때문에 이를 사용한다
delimiter |
create trigger chat_backup
before delete on chat for each row
begin
insert into backup(chat_id, backup_msg)
values(old.chat_id, old.msg);
end
|
# 트리거 리스트 확인
show triggers;
# chat 테이블에 데이터 추가
insert into chat(msg)
values ("hello"), ("hi"), ("goodbye");
# delete 쿼리 실행해서 트리거 동작 확인
delete from chat
where msg = "hello"
limit 10;
select * from chat;
select * from backup;
show progresslist();
# 트리거 생성
delimiter |
create trigger chat_backup
before delete on chat for each row
begin
insert into backup(chat_id, backup_msg)
value (old.chat_id, old.msg);
end
|
# 트리거 리스트 확인
show triggers;
# chat 테이블에 데이터 추가
insert into chat(msg)
values ("hello"), ("hi"), ("hello");
select * from chat;
# delete 쿼리 실행해서 트리거 동작 확인
delete from chat
where msg = "hello"
limit 10;
select * from chat;
# 백업 테이블 확인
select * from backup;
# backup
# workbench를 이용해서 백업
# .csv, .sql
use world;
create database backup;
use backup;
show tables;
select * from backup;
use world;
select * from country;
# 1. 멕시코(Mexico)보다 인구가 많은 나라이름과 인구수를 조회하시고 인구수 순으로 내림차순하세요
select name, population
from country
where population >= (
select population
from country
where name = 'mexico'
)
order by population desc;
# 2. 국가별 몇개의 도시가 있는지 조회하고 도시수 순으로 10위까지 내림차순하세요.
select country.name, count(country.name) as count
from country
join city
on country.code = city.countrycode
group by country.name
order by count desc
limit 10;
#3. 언어별 사용인구를 출력하고 언어 사용인구 순으로 10위까지 내림차순하세요.
# 1. join country, countrylanguage
# 2. country population, countrylanguage percentage > language population
# 3. group by language
select countrylanguage.language, round(sum(country.population * countrylanguage.percentage)) as count
from country
join countrylanguage
on country.code = countrylanguage.countrycode
group by countrylanguage.language
order by count desc
limit 10;
select * from countrylanguage;
select * from country;
#Quiz 7. 한국와 미국의 인구와 GNP를 세로로 아래와 같이 나타내세요. (쿼리문에 국가 코드명을 문자열로 사용해도 됩니다.)
select "population" as "category", round((select population from country where code= "KOR")) as KOR
, round((select population from country where code= "USA")) as USA
union
select "gnp" as "category", round((select gnp from country where code= "KOR")) as KOR
, round((select gnp from country where code= "USA")) as USA;
'Python활용 빅데이터전문가과정' 카테고리의 다른 글
| 210111 MON - 파이썬 기본문법 (2) (0) | 2021.01.13 |
|---|---|
| 210108 FRI 수업 - 파이썬 기본문법(1) (0) | 2021.01.10 |
| 210106 WED 수업 - MySQL 문법(2) (0) | 2021.01.06 |
| 210105 TUE 수업 - MySQL 문법(1) (0) | 2021.01.05 |
| 210104 MON 수업 (0) | 2021.01.04 |


